The long awaited ChatGPT model, codenamed Strawberry, has officialy launched as the o1 model. As usual, the results are ground breaking and take us a step closer to the ultimate goal of creating an AGI (Artificial General Intelligence).
Chain of thought
Previous ChatGPT models were prone to forget what had been mentioned earlier in the conversation, even by themselves. This has been addressed in the new o1 models with the chain of thought capability. Simply put, they are capable of delivering step by step answers following a logical chain of reasoning.
This has allowed it to surpass PhD level humans at answering science questions, and far surpassed ChatGPT 4 at competitive math and code questions.
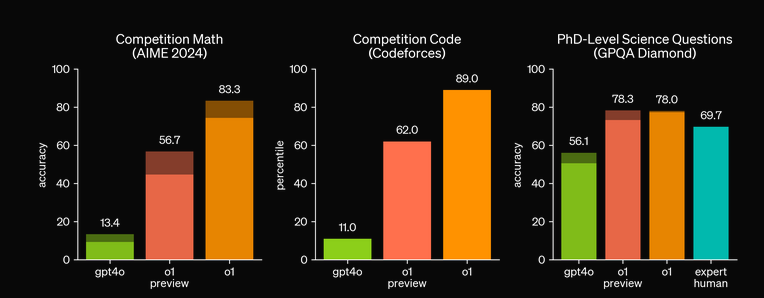
openai.com/index/learning-to-reason-wtih-llms
Chain of thought does come with a slight downside, where the model will take a few seconds, typically around 60, to formulate an answer before responding.
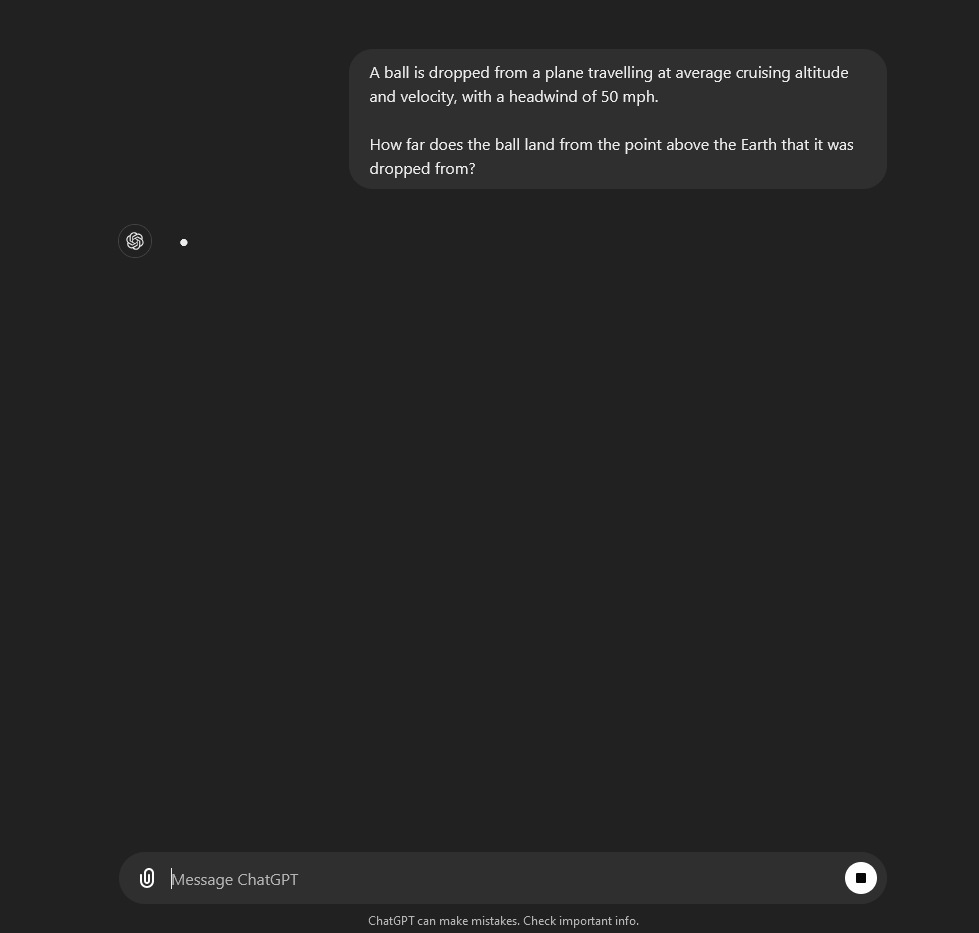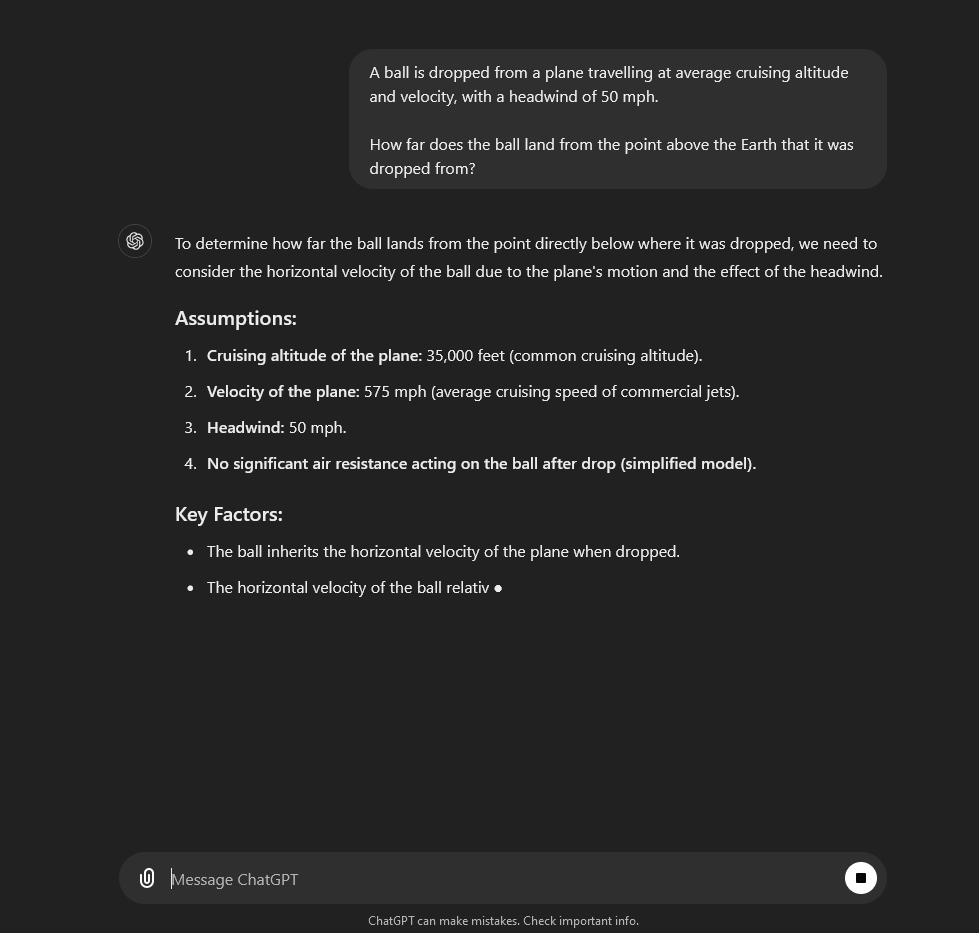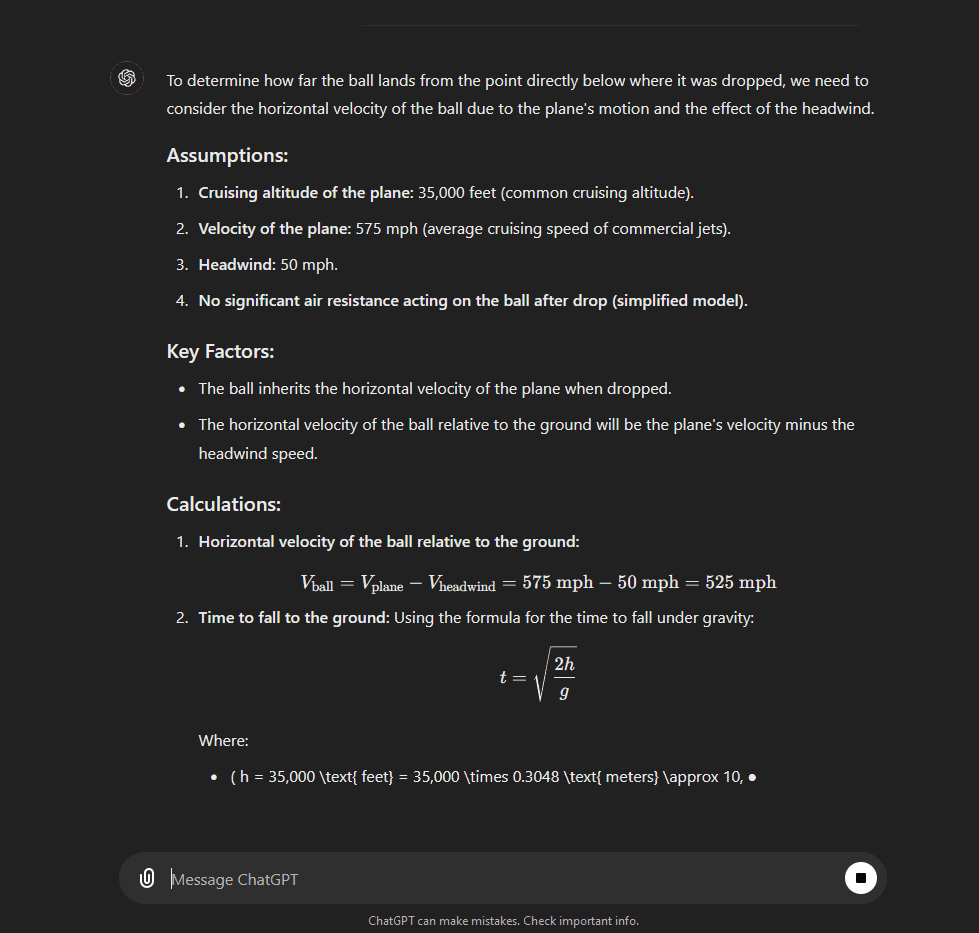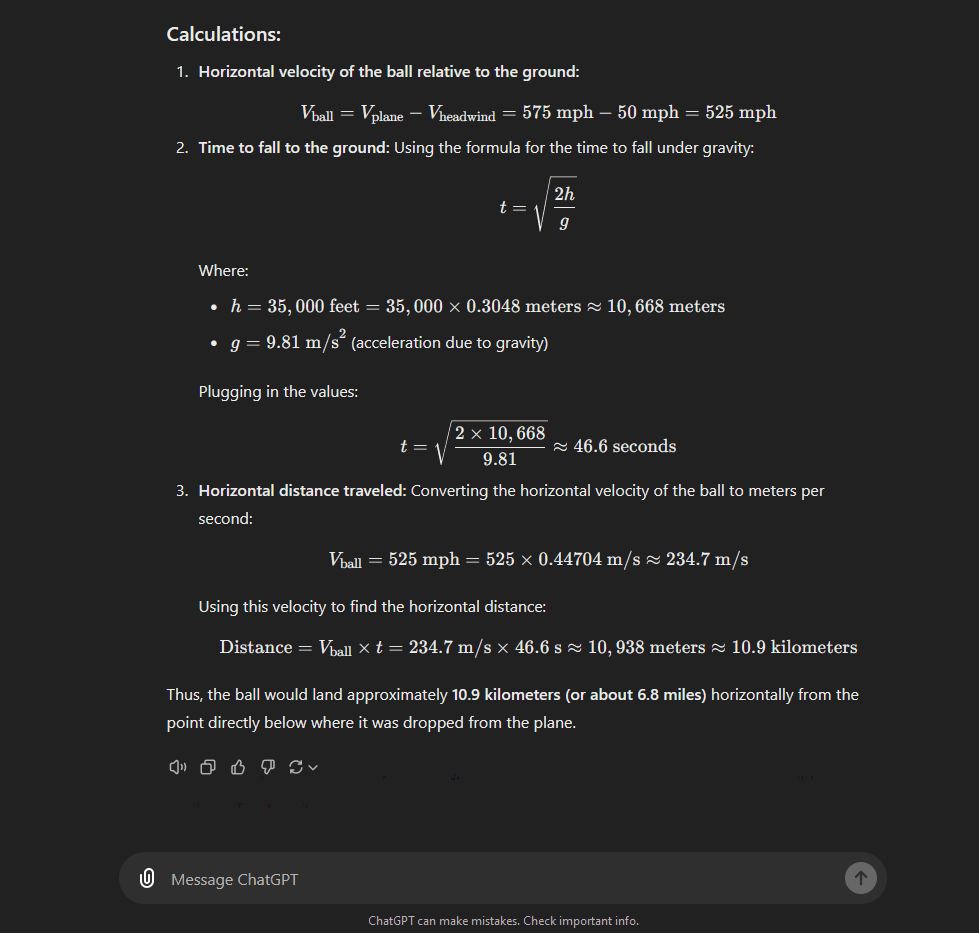
You can see the difference between the two models in the GIFs above, where both models are asked a question about a ball being dropped from a plane.
4o starts responding immediately, whereas 1o-preview takes 51 seconds to think, and goes through steps reasoning about the solution. As a result, 1o-preview is able to provide a more detailed answer, which not only explains the steps in more detail, but also gives a more nuanced answer taking into consideration air resistance.
Hiding the Chain of Thought
One interesting point made by OpenAI, is that the chain of thought can be used to monitor what the model is “thinking”. This was previously a blind spot in LLM’s, since no one is capable of fully understanding their inner-workings, it was not possible to see how they arrived at an answer.
OpenAI decided to not fully reveal the chain of thought to users. The reasons they give include maintaing a competitive edge and giving the model freedom of thought. This comes into play with OpenAI’s AI safety agenda. Where they wish to monitor the AI for signs of manipulating the user, something that a policy restricting the chain of thought can hinder.
Q*
An early codename for the o1 model was Q*. Which caused controversy with the OpenAI board firing the CEO, Sam Altman, for apparently misleading them on it’s capabilities as an AGI. Then with the backing of Microsoft, Sam returned as the CEO and much of the original board member were forced to resign.
An interesting point about Q* is that it gave an insight into how the new model was trained. This references the Q-learning reinforcement learning algorithm. A type of machine learning which involves setting a goal and giving an AI agent free reign to learn the rules for achieving it. This allows the agent an internal representation of how the world operates. This algorithm has been used to great effect in the past for teaching AI agents how to play games.
OpenAI is not the only organisation that has had success combining reinforcement learning (RL) with LLM’s. Google recently released a paper of their GameNGen model, which generated a playable version of Doom. This was achieved by teaching an agent how to play Doom using RL and then use that to create training data for a Stable Diffusion v1.4 model which renders the game.
Conclusion
Chain of thought reasoning is the next logical step in achieving an AGI. Since it helps the model to achieving “common sense”, which has eluded the LLMs so far.
Other teams have attempted to fill this gap in the past, such as with Devin – The AI developer. But with this new offering from OpenAI providing similar functionality, it lowers the barrier of entry for other teams to create something similar.
As a result, this is likely to have an impact on knowledge based industries such as software engineering by boosting productivity.