The fable of “The Crow and the Pitcher” was commented on in the 4th-5th century by Avianus, that “thoughtfulness is superior to brute strength“.

This echoed true in the latest news from the quickly evolving AI frontier. When DeepSeek released their open source DeepSeek-R1 model, based on DeepSeek-V3 on 20th January 2025. This is a chain-of-thought model rivaling OpenAI’s flagship o1 reasoning model. With claims of training costs being $6 million, compared to GPT-4’s $100 million training cost.
Sanctions and Innovation
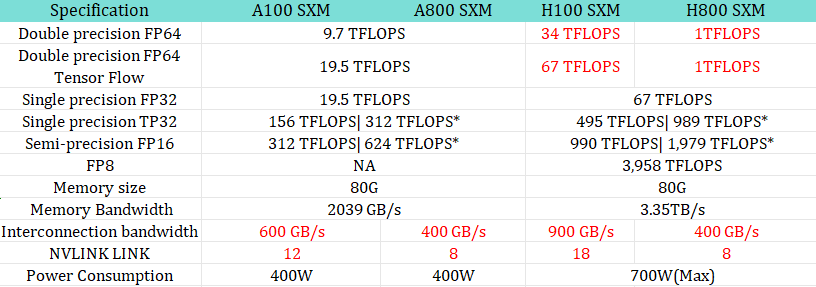
DeepSeek is owned by the Chinese quantitive trading firm, High-Flyer, operating under CEO Liang Wenfeng. Making the company subject to United States sanctions. Which limit exports of AI chips to those less powerful than Nvidia A100’s.
This primarily means that exported chips must have:
- An I/O bandwidth speed (communication speed within the chip and externally) of less than 600 G bytes/s.
- The bit length of each operation multiplied by the raw TOPS (Tera / Trillion Operations per Second) must be less than 4800 TOPS.
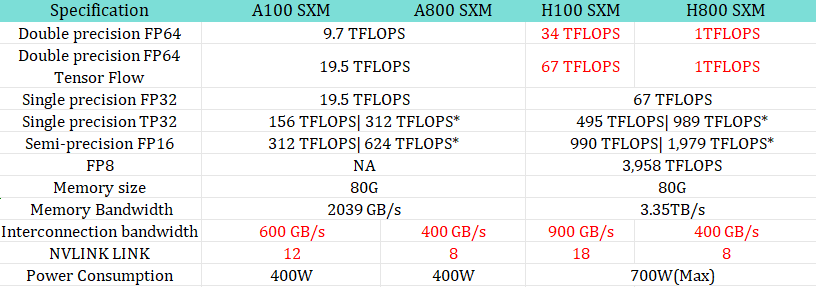
Nvidia tailored their H800 range of chips, used for DeepSeek training, for the Chinese market:
- Reduced interconnect speed (communication speed within the chip) from 600 GB/s used for the A100 chips to 400 GB/s.
- Made double precision operations practically unusable, by reducing their speed to 1 TFLOPS.
- NVLinks kept at 8, compared to H100’s 18. These are buses which speed up GPU to GPU communication.
The 1.76 trillion parameter GPT-4 was trained on 25,000 A100 GPU’s for 100 days. In contrast, the 671 billion parameters DeepSeek-V3 model was trained on 2,048 H800 GPU’s for about 60 days.
To achieve this DeepSeek bypassed the CUDA software which ships with Nvidia chips, and is used across the industry. Instead, they used Nvidia’s PTX (Parallel Thread Execution) low level language to implement optimized functions. PTX is one level above low-level machine code, which is used to operate the GPU processing cores.
This allowed 20 out of 132 streaming microprocessors to be reserved for server communication, compensating for bandwidth limitations. Presumably by compressing data streams. Advanced pipeline algorithms were also implemented by the DeepSeek engineers, for thread / warp fine-tuning, which is notoriously difficult to do and is a testament to their skill.
DeepSeek-V3 also uses a Mixture-of-Experts (MoE) architecture. Which is a collection of models, each fine-tuned for specific tasks, that only activate when needed. Allowing only 37 billion out of 571 billion parameters to be activated for each token, providing further efficiency gains. However, MoE architecture is not new and is also used by ChatGPT-4.
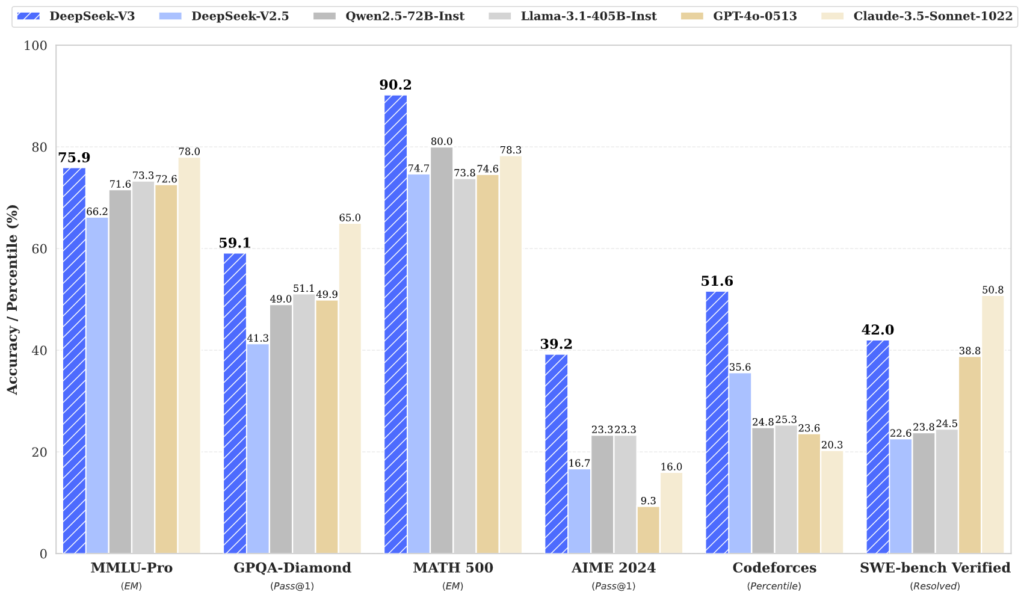
The performance of DeepSeek-V3 in comparison to it’s counter-parts shows that it achieves a better accuracy on most benchmarks:
Market Reaction
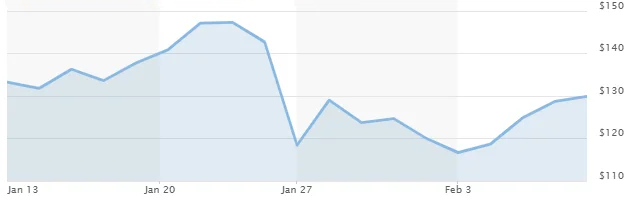
The economic effect of the release has been noticeable. With the DeepSeek chat app taking over the ChatGPT app, to become the most downloaded on the iOS store. As well as an almost 20% decline in Nvidia’s share price , as investors questioned whether the newest chips are a necessity for training the latest generation of AI models:
Open Source
Possibly more interesting, is the fact that DeepSeek is open source, with it’s code available on GitHub. In contrast to “OpenAI” models, whose source code is not available to the general public.
The reason for making the code open source, may be to foster innovation but to also help allay fears that DeepSeek is being used to exfiltrate data. A concern which has led to countries such as the U.S, South Korea, Taiwan and Australia banning it’s use on government devices.
However, for non government consumers who want to protect their data, there is the option to download the model and run it on an isolated network.


{kind=link}
{kind=link}